



Uncertainty estimation and ensembling methods go hand-in-hand. Uncertainty estimation is one of the main benchmarks for assessment of ensembling performance. At the same time, deep learning ensembles have provided state-of-the-art results in uncertainty estimation. In this work, we focus on in-domain uncertainty for image classification. We explore the standards for its quantification and point out pitfalls of existing metrics. Avoiding these pitfalls, we perform a broad study of different ensembling techniques. To provide more insight in this study, we introduce the deep ensemble equivalent score (DEE) and show that many sophisticated ensembling techniques are equivalent to an ensemble of only few independently trained networks in terms of test performance.


Pitfalls of metrics Many common metrics of in-domain uncertainty estimation (e.g. log-likelihood, Brier score, calibration metrics, etc.) are either not comparable across different models or fail to provide a reliable ranking. For instance, although temperature scaling is not a standard for ensembling techniques, it is a must for a fair evaluation. Without calibration, the value of the log-likelihood, as well as the ranking of different methods may change drastically depending on the softmax temperature which is implicitly learned during training. Since no method achieves a perfect calibration out-of-the-box yet, comparison of the log-likelihood should only be performed at the optimal temperature.
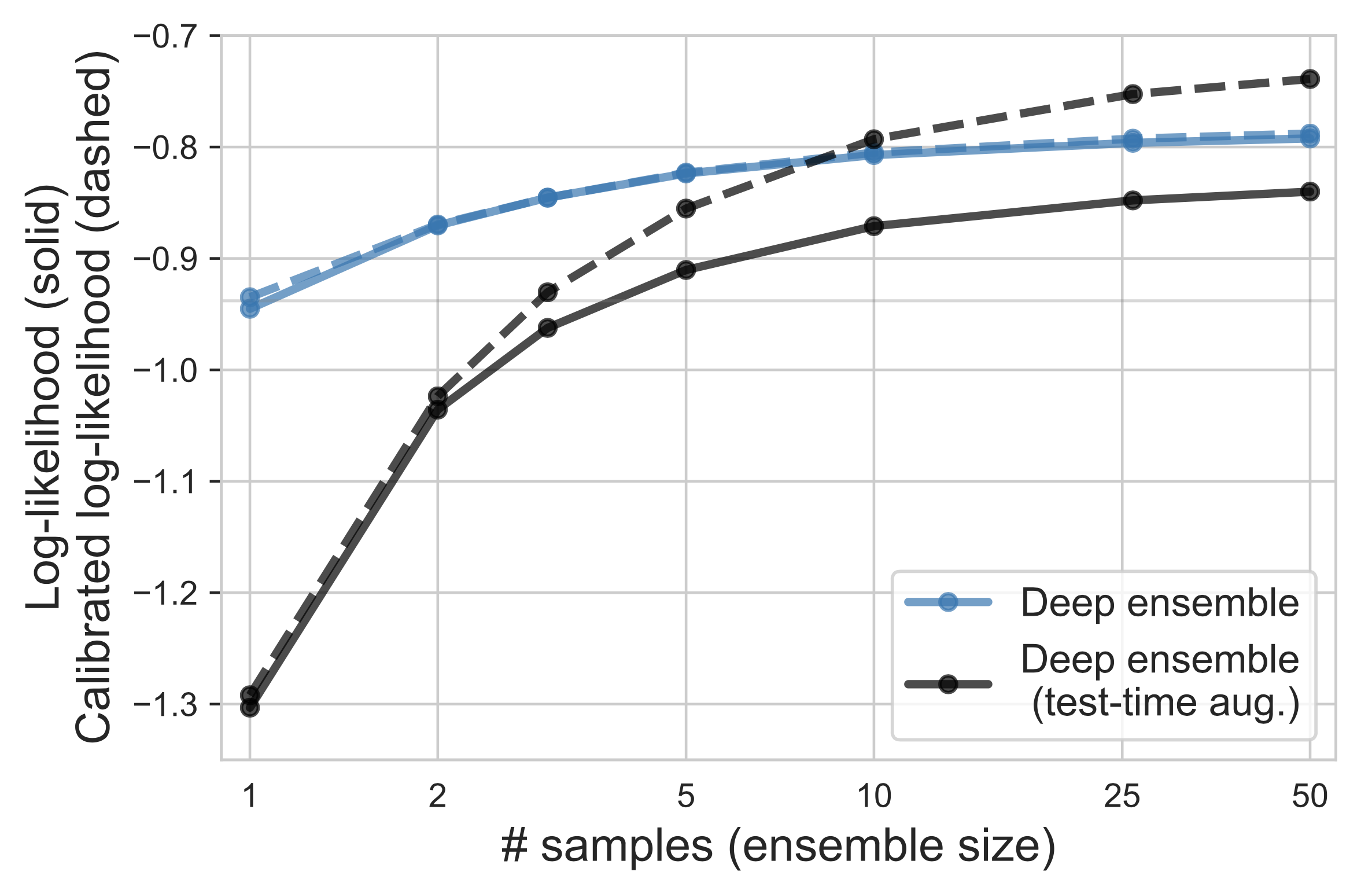
Example: The average log-likelihood (LL) of two ensembling techniques before (solid) and after (dashed) temperature scaling. Without temperature scaling test-time data augmentation decreases the log-likelihood of plain deep ensembles. However, when temperature scaling is enabled, deep ensembles with test-time data augmentation outperform plain deep ensembles.
Pitfalls of ensembles Most of the popular ensembling techniques—one of the major tools for uncertainty estimation—require averaging predictions across dozens of members of an ensemble, yet are essentially equivalent to an ensemble of only few independently trained models.
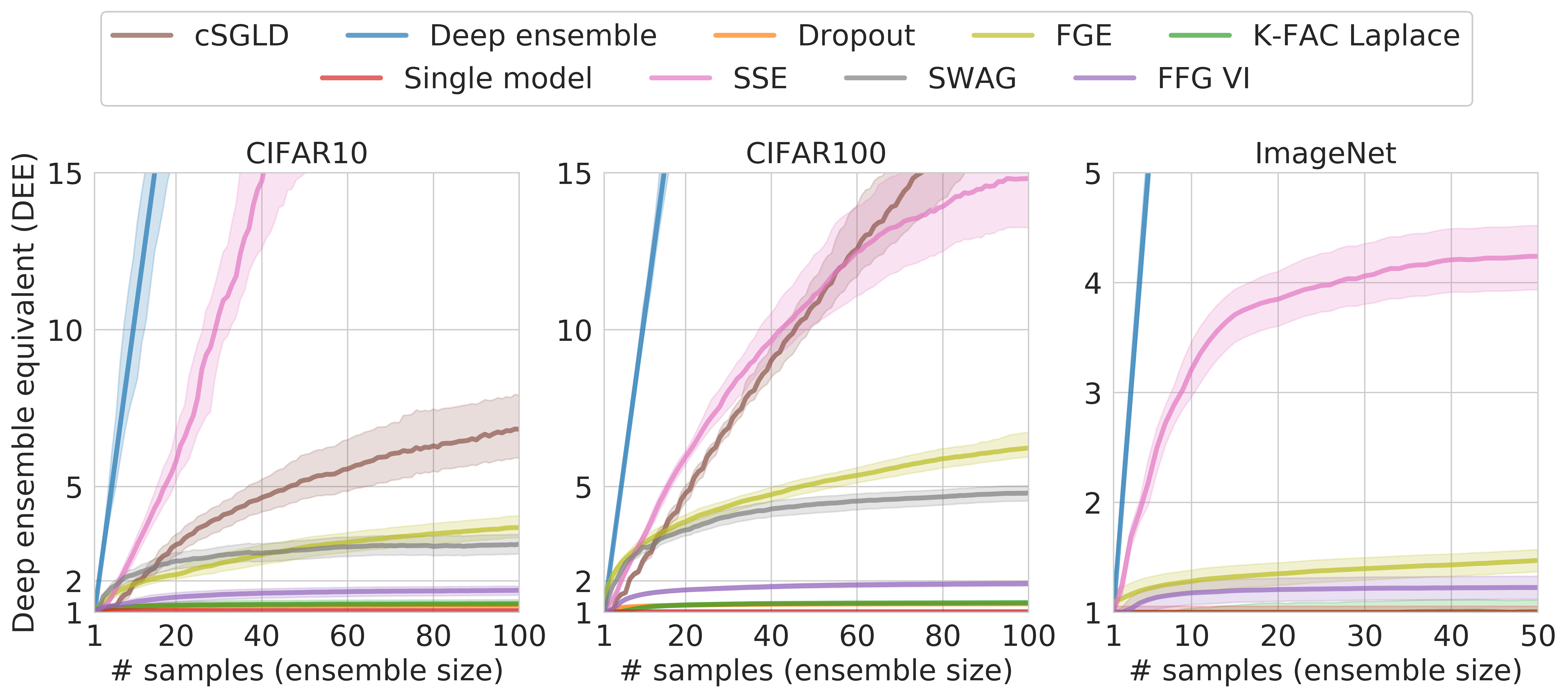
The deep ensemble equivalent score (DEE) of a model is equal to the minimum size of a deep ensemble (an ensemble of independently train networks) that achieves the same performance as the model under consideration. The plot demonstrates that all of the ensembling techniques are far less efficient than deep ensembles during inference.
Example: If an ensemble achieves DEE score 5.0 after averaging of predictions of 100 networks, it means that the ensemble has the same performance as a deep ensemble of only 5 models of the same architecture.
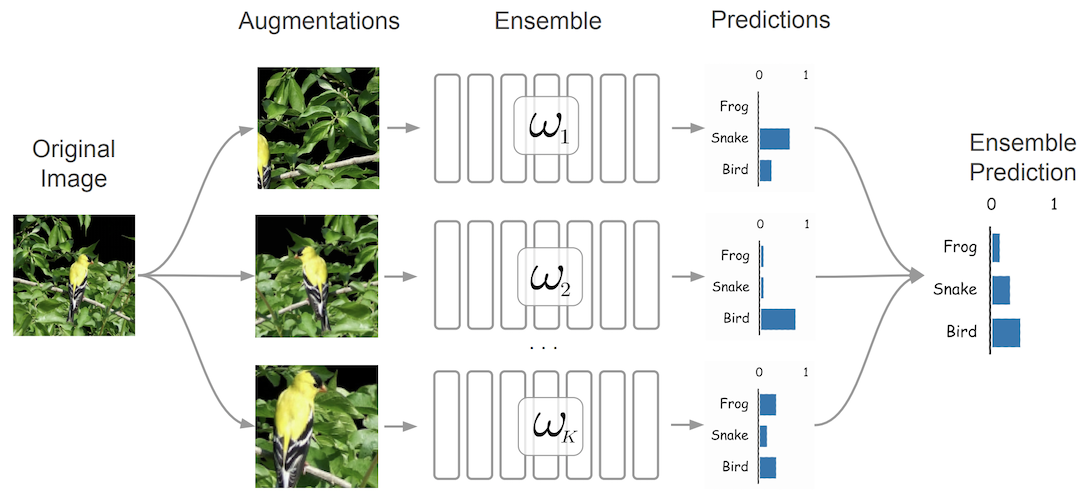
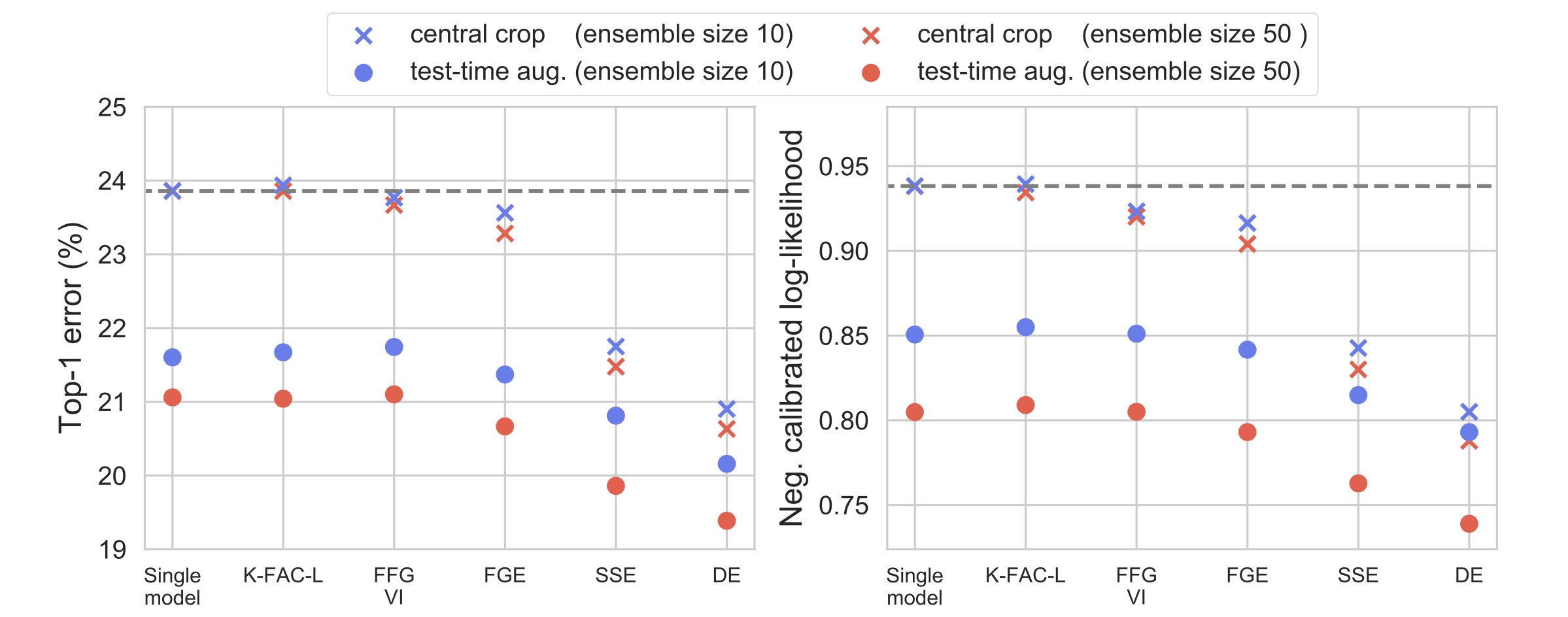
Missing part of ensembling Test-time data augmentation improves both calibrated log-likelihood and accuracy of ensembles for free! Test-time data augmentation simply computes the prediction of every member of the ensemble on a single random augmentation of an image. Despite being a popular technique for large-scale image classification problems, test-time data augmentation seems to be overlooked in the community of uncertainty estimation and ensembling.
The webpage template was borrowed from Dmitry Ulyanov.
@article{ashukha2020pitfalls,
title={Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning},
author={Ashukha, Arsenii and Lyzhov, Alexander and Molchanov, Dmitry and Vetrov, Dmitry},
journal={arXiv preprint arXiv:2002.06470},
year={2020}
}


