
|
Email / CV / Google Scholar / GitHub / Twitter / 📍London (UK) |

|

|
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, Victor Lempitsky WACV, 2022 project page / poster video (5 mins) / arXiv / code / bibtex / Yannic Kilcher / Casual GAN LaMa generalizes surprisingly well to much higher resolutions (~2k❗️) than it saw during training (256x256), and achieves the excellent performance even in challenging scenarios, e.g. completion of periodic structures. |
|
Arsenii Ashukha*, Alexander Lyzhov*, Dmitry Molchanov*, Dmitry Vetrov ICLR, 2020 blog post / poster video (5mins) / code / arXiv / bibtex The work shows that i) a simple ensemble of independently trained networks performs significantly better than recent techniques ii) a simple test-time augmentation applied to a conventional network outperforms low-parameters ensembles (e.g. Dropout) and also improves all ensembles for free iii) comparison of uncertainty estimation ability of algorithms is often done incorectly in literature. |
|
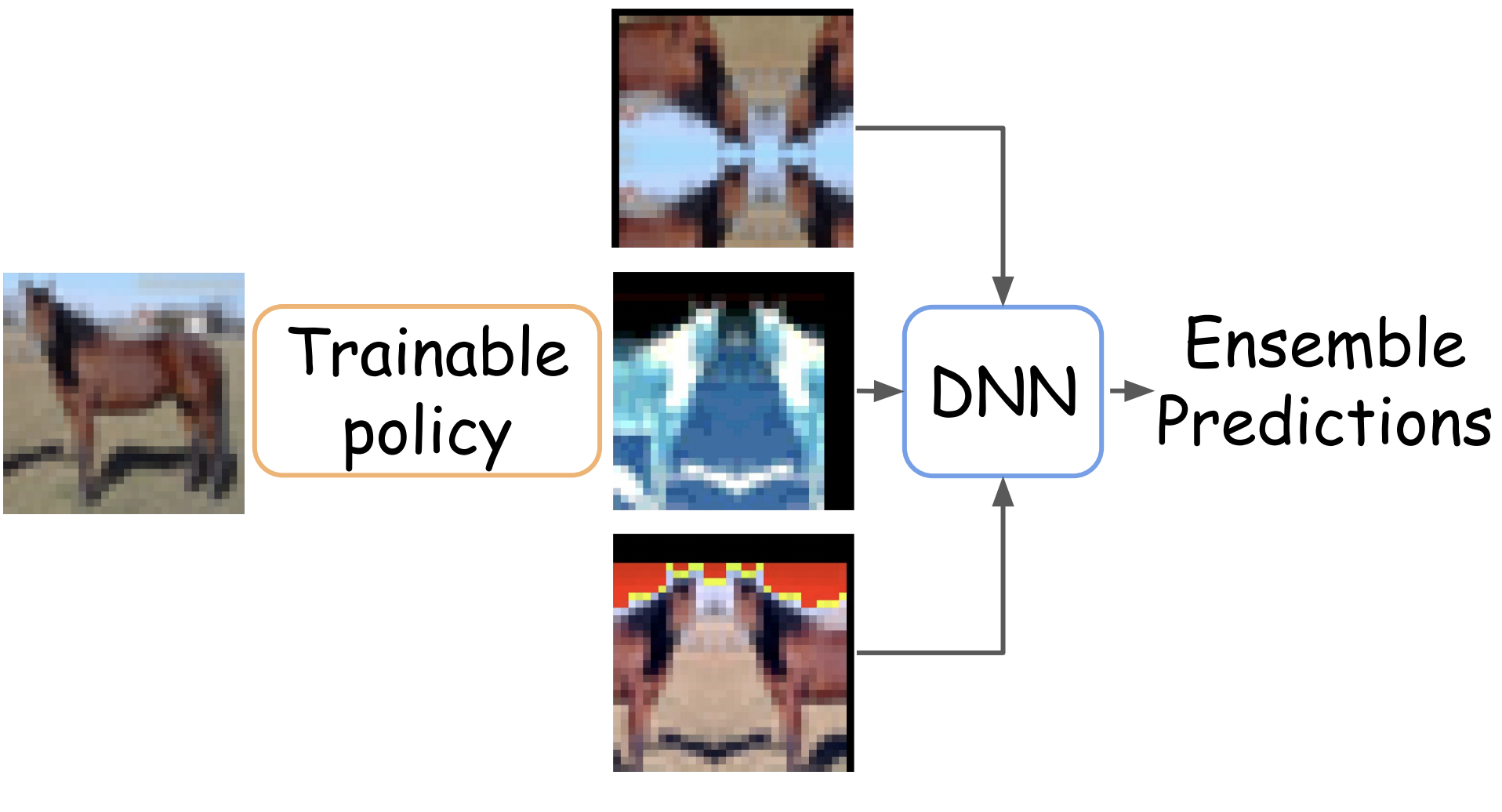
Arsenii Ashukha*, Dmitry Molchanov*, Alexander Lyzhov*, Yuliya Molchanova*, Dmitry Vetrov UAI, 2020 code / arXiv / slides / bibtex We introduce greedy policy search (GPS), a simple but high-performing method for learning a policy of test-time augmentation. |
|
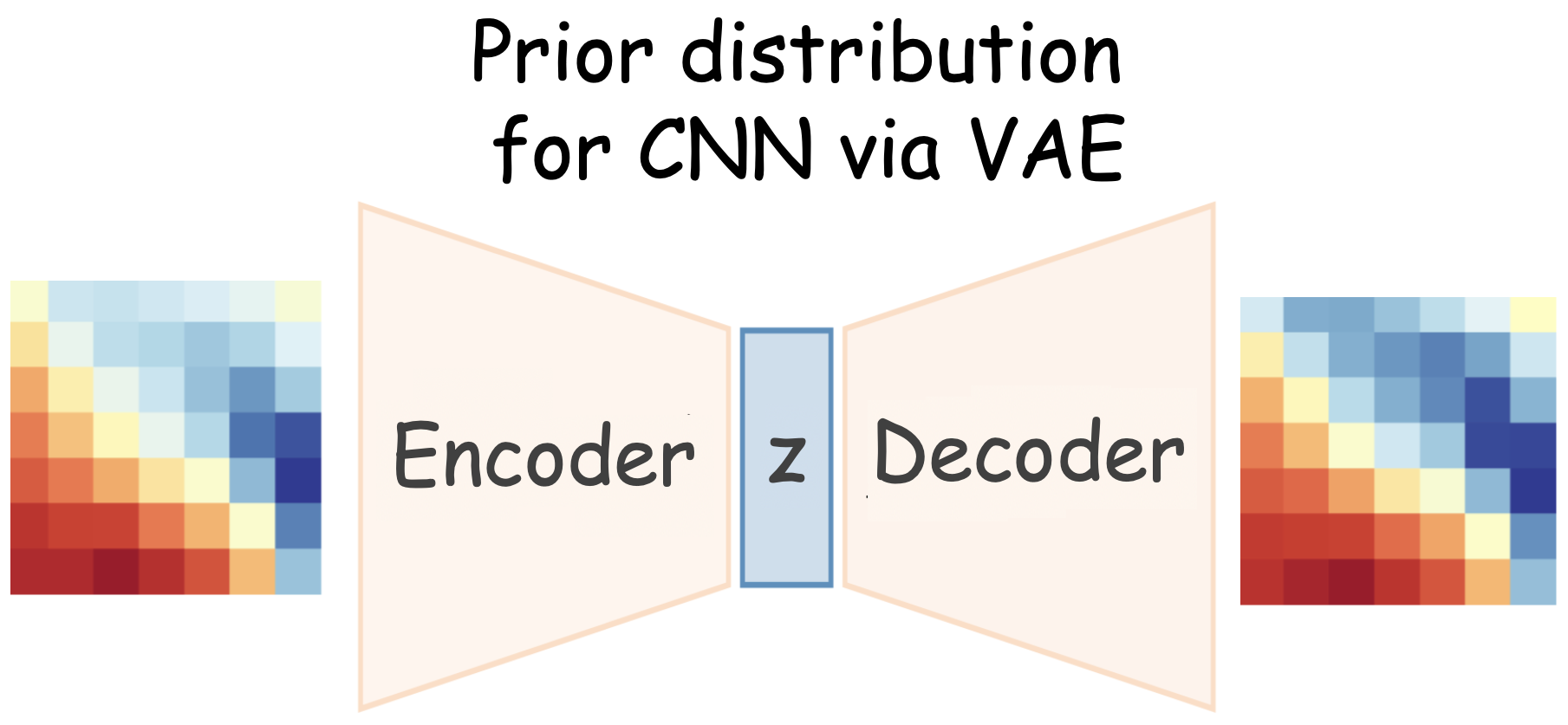
Arsenii Ashukha*, Andrei Atanov*, Kirill Struminsky, Dmitry Vetrov, Max Welling ICLR, 2019 code / arXiv / bibtex The deep weight prior is the generative model for kernels of convolutional neural networks, that acts as a prior distribution while training on new datasets. |
|
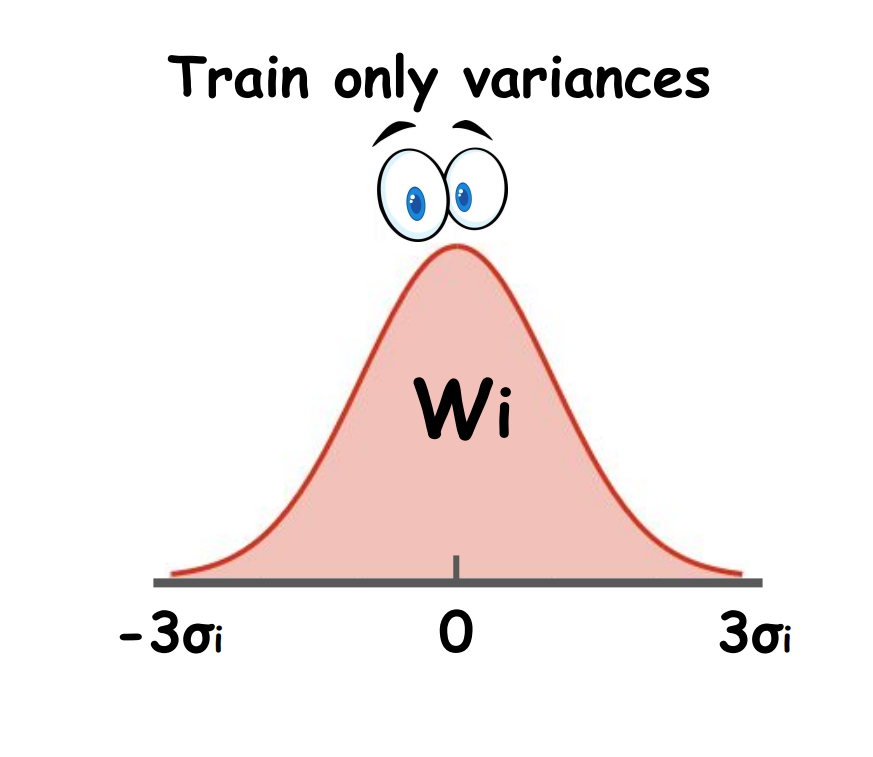
Arsenii Ashukha*, Kirill Neklyudov*, Dmitry Molchanov*, Dmitry Vetrov ICLR, 2019 code / arXiv / bibtex It is possible to learn a zero-centered Gaussian distribution over the weights of a neural network by learning only variances, and it works surprisingly well. |
|
Andrei Atanov, Alexandra Volokhova, Arsenii Ashukha, Ivan Sosnovik, Dmitry Vetrov INNF Workshop at ICML, 2019 code / arXiv / bibtex We employ semi-conditional normalizing flow architecture that allows efficiently trains normalizing flows when only few labeled data points are available. |
|
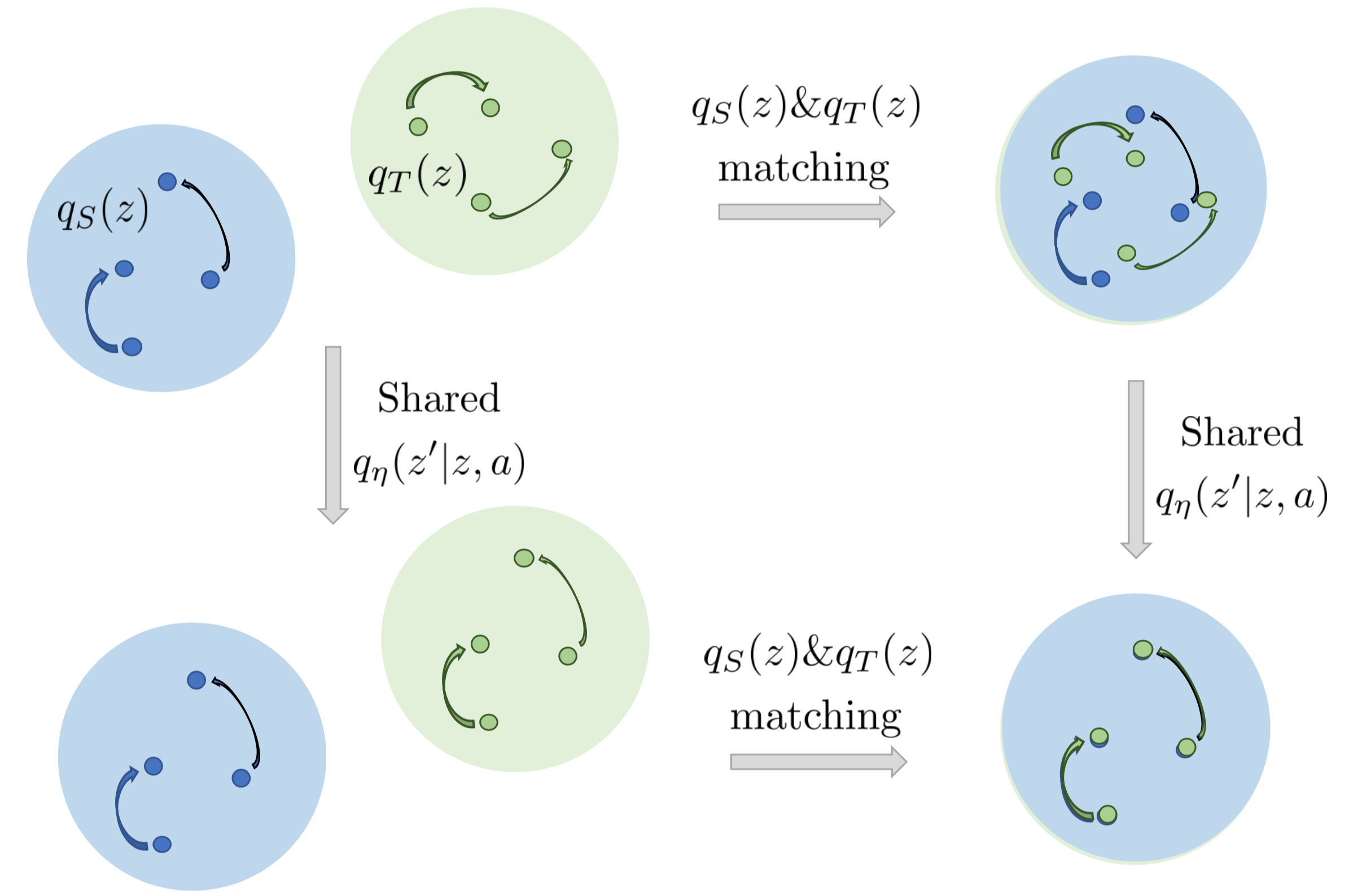
Evgenii Nikishin, Arsenii Ashukha, Dmitry Vetrov BLD Workshop at NeurIPS, 2019 code / poster Domain adaptation via learning shared dynamics in a latent space with adversarial matching of latent states. |
|
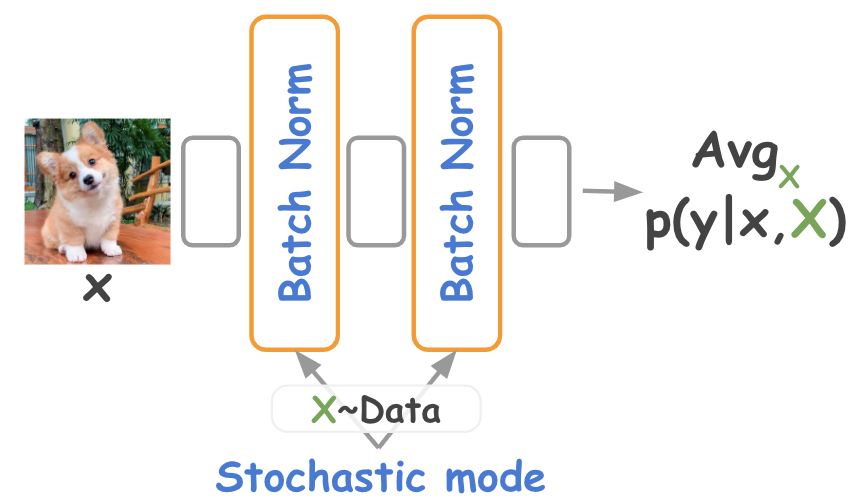
Andrei Atanov, Arsenii Ashukha, Dmitry Molchanov, Kirill Neklyudov, Dmitry Vetrov Joint Workshop Track at ICLR, 2018 code / arXiv Inference-time stochastic batch normalization improves the performance of uncertainty estimation of ensembles. |
|
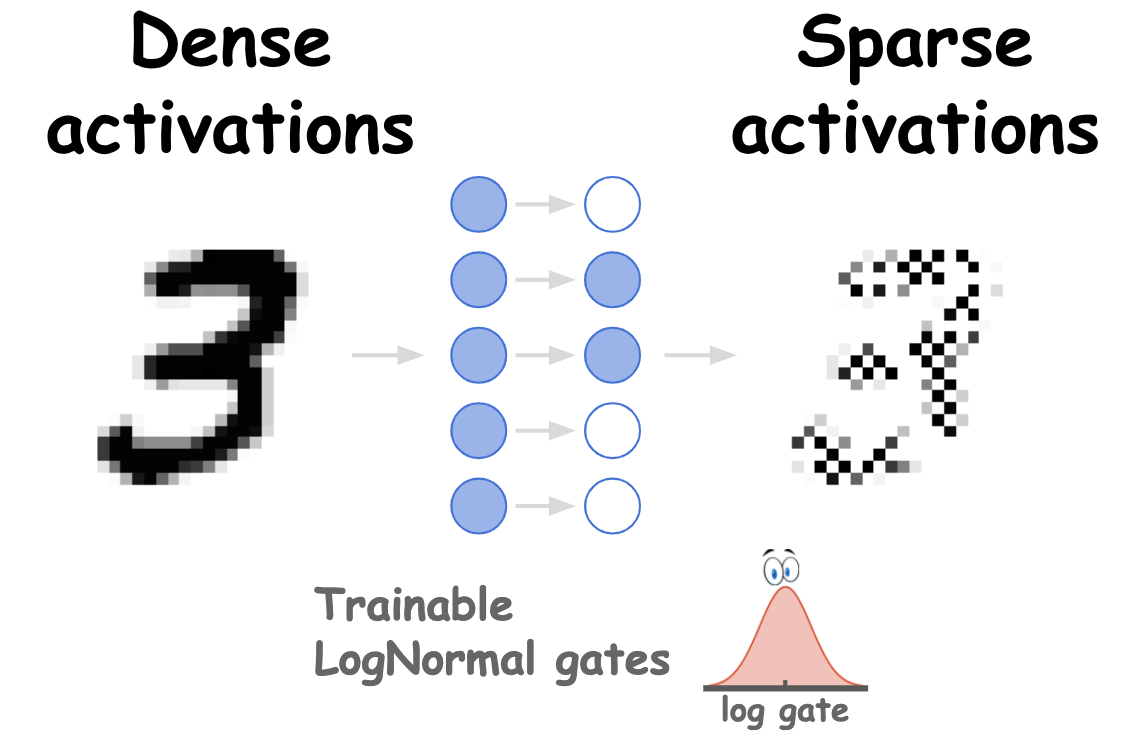
Kirill Neklyudov, Dmitry Molchanov, Arsenii Ashukha, Dmitry Vetrov NeurIPS, 2017 code / arXiv / bibtex / poster The model allows to sparsify a DNN with an arbitrary pattern of spasticity e.g., neurons or convolutional filters. |
|
Arsenii Ashukha*, Dmitry Molchanov*, Dmitry Vetrov ICML, 2017 retrospective⏳ / talk (15 mins) / arXiv / bibtex / code (theano, tf by GoogleAI, colab pytorch) Variational dropout secretly trains highly sparsified deep neural networks, while a pattern of sparsity is learned jointly with weights during training. |
* denotes joint first co-authorship.
|
Check out very short and simple and fan to make implementations of ML algorithms: Also, chek out more solid implementations (at least they can do ImageNet): |
|
The webpage template was borrowed from Jon Barron.
|